A Preliminary Contamination-Free Evaluation of Reasoning Models
LRM-Eval
We present a moderate-scale evaluation of contemporary large reasoning models designed to minimize contamination. Our preliminary analyses also reveal some intriguing behaviors of reasoning. We also release ROME, our evaluation benchmark for vision-language models designed to assess reasoning from visual evidence.
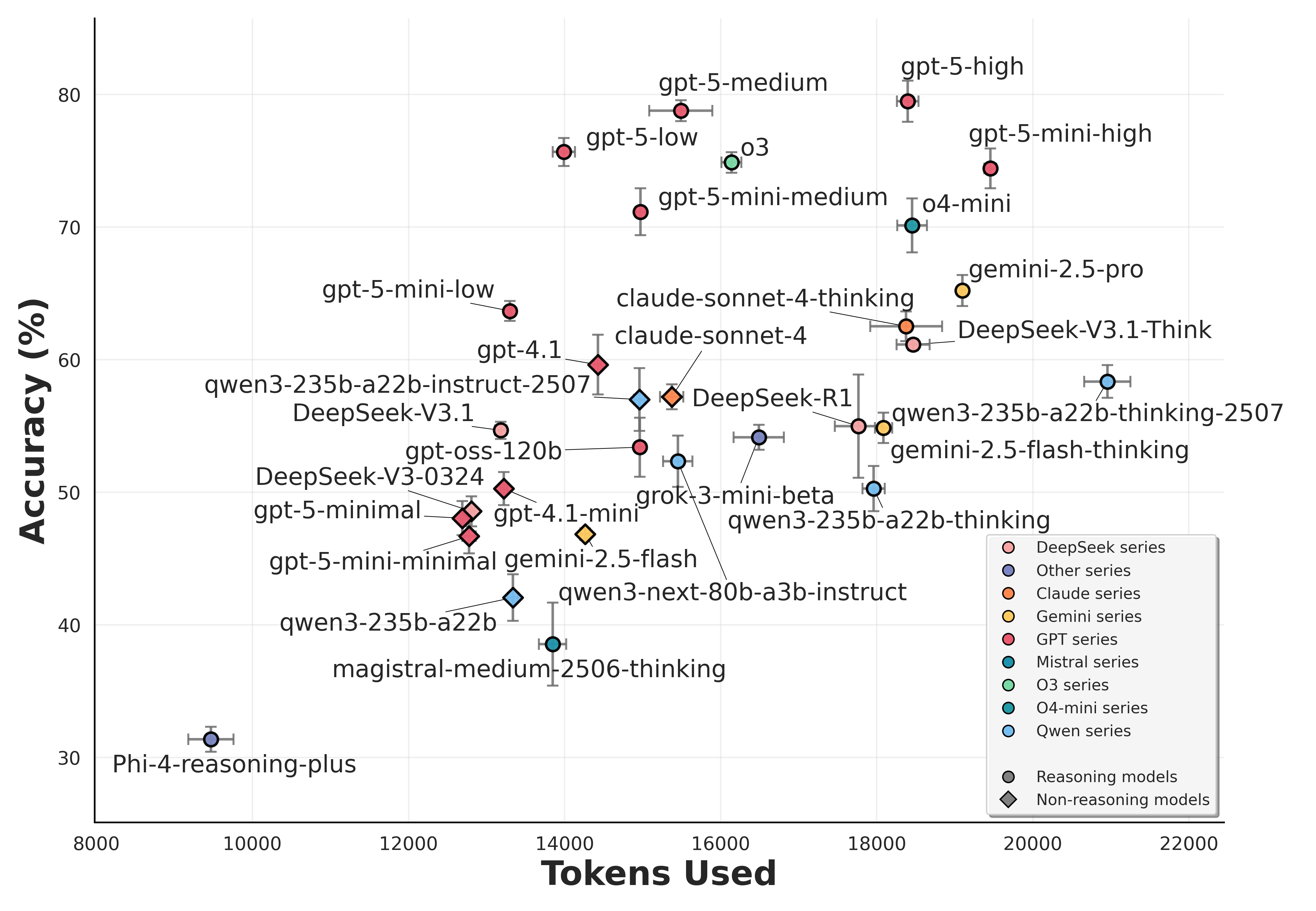
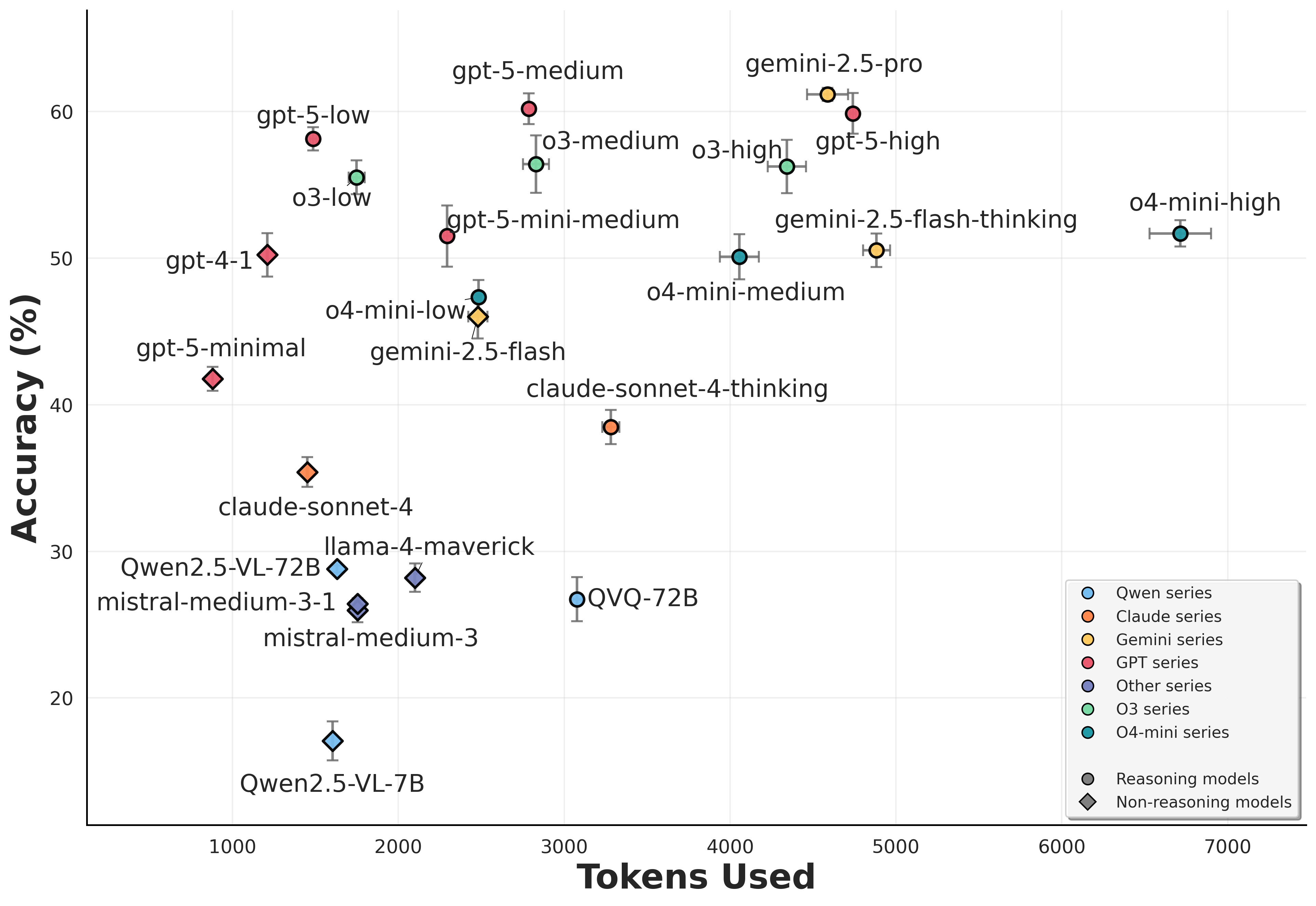
Overall Performance
We evaluate modern LRMs on textual and visual reasoning tasks (four runs for each prompt). The scatter plots display the mean ± standard deviation of overall accuracy versus token usage.
Textual problems
Visual problems
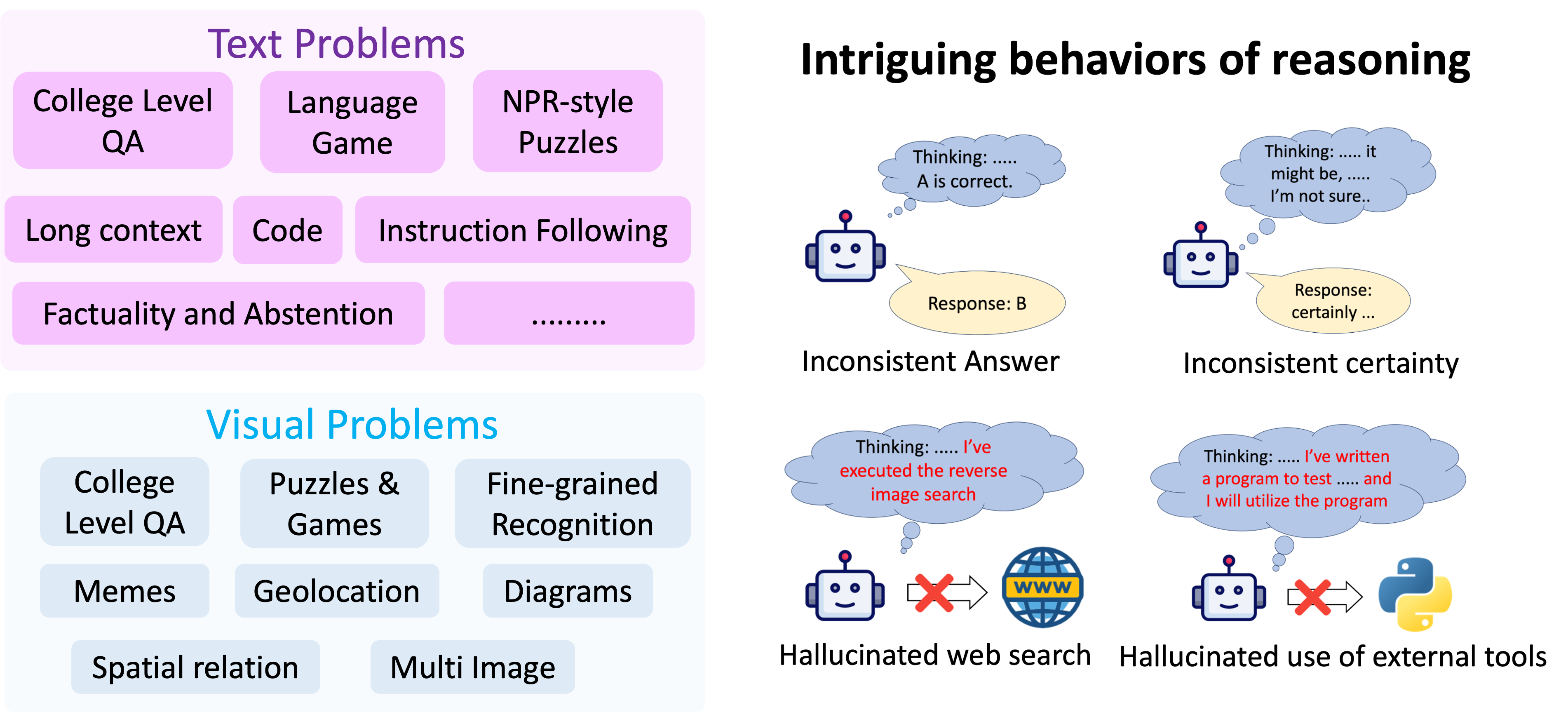
Intriguing behaviors of reasoning
(Click on any example image to view a detailed example of the observed behavior)
| Behavior | Example |
|---|---|
Inconsistent Answer  Answer in the actual response may sometimes differ from what has been concluded in reasoning |  |
Inconsistent Certainty  The actual response may still state in a certain, deterministic tone even when obvious uncertainty has been acknowledged in reasoning |  |
Hallucinated Web Search  Models may pretend to have conducted a web search with fabricated results |  |
Hallucinated Tool Use  Models may pretend to have used external tools |  |
Detailed Results
Course questions
College-level questions from course and lecture materials across STEM, humanities, and social sciences.
NYT Connections
The Connections game by The New York Times.
NPR-style puzzles
New puzzles emulating the style of the NPR Sunday Puzzle.
Deciphering
Decipher text containing encrypted or hidden information.
LeetCode
Coding problems from recent weekly and biweekly LeetCode contests.
Instruction following
Generated, verifiable instructions with few-shot examples from IFEval.
Multi-turn instructions
Includes reminders and triggers, role-playing, and explaining concepts in prescribed ways.
Long-context queries
Manually written questions requiring understanding of long arXiv papers (LaTeX source).
Factuality and abstention
Long-tailed knowledge that is very infrequent in web-scale corpora.
Evaluation Metrics: Overall scores are not available for textual tasks due to the use of different evaluation metrics across benchmarks. Visual task accuracy is computed using multiple types of evaluators—please refer to our GitHub repository for details.
| Rank | Model | Organization | Accuracy ± Std (avg@4) | Link |
|---|---|---|---|---|
| See our technical report for more details. | ||||
Citation
@misc{qin2025flageval,
title={FlagEval Findings Report: A Preliminary Evaluation of Large Reasoning Models on Automatically Verifiable Textual and Visual Questions},
author={Bowen Qin and Chen Yue and Fang Yin and Hui Wang and JG Yao and Jiakang Liu and Jing-Shu Zheng and Miguel Hu Chen and Richeng Xuan and Shibei Meng and Shiqi Zhou and Teng Dai and Tong-Shuai Ren and Wei Cui and Xi Yang and Xialin Du and Xiaojing Xu and Xue Sun and Xuejing Li and Yaming Liu and Yesheng Liu and Ying Liu and Yonghua Lin and Yu Zhao and Yunduo Zhang and Yuwen Luo and Zheqi He and Zhiyuan He and Zhongyuan Wang},
year={2025},
eprint={2509.17177},
archivePrefix={arXiv},
primaryClass={cs.CL}
}