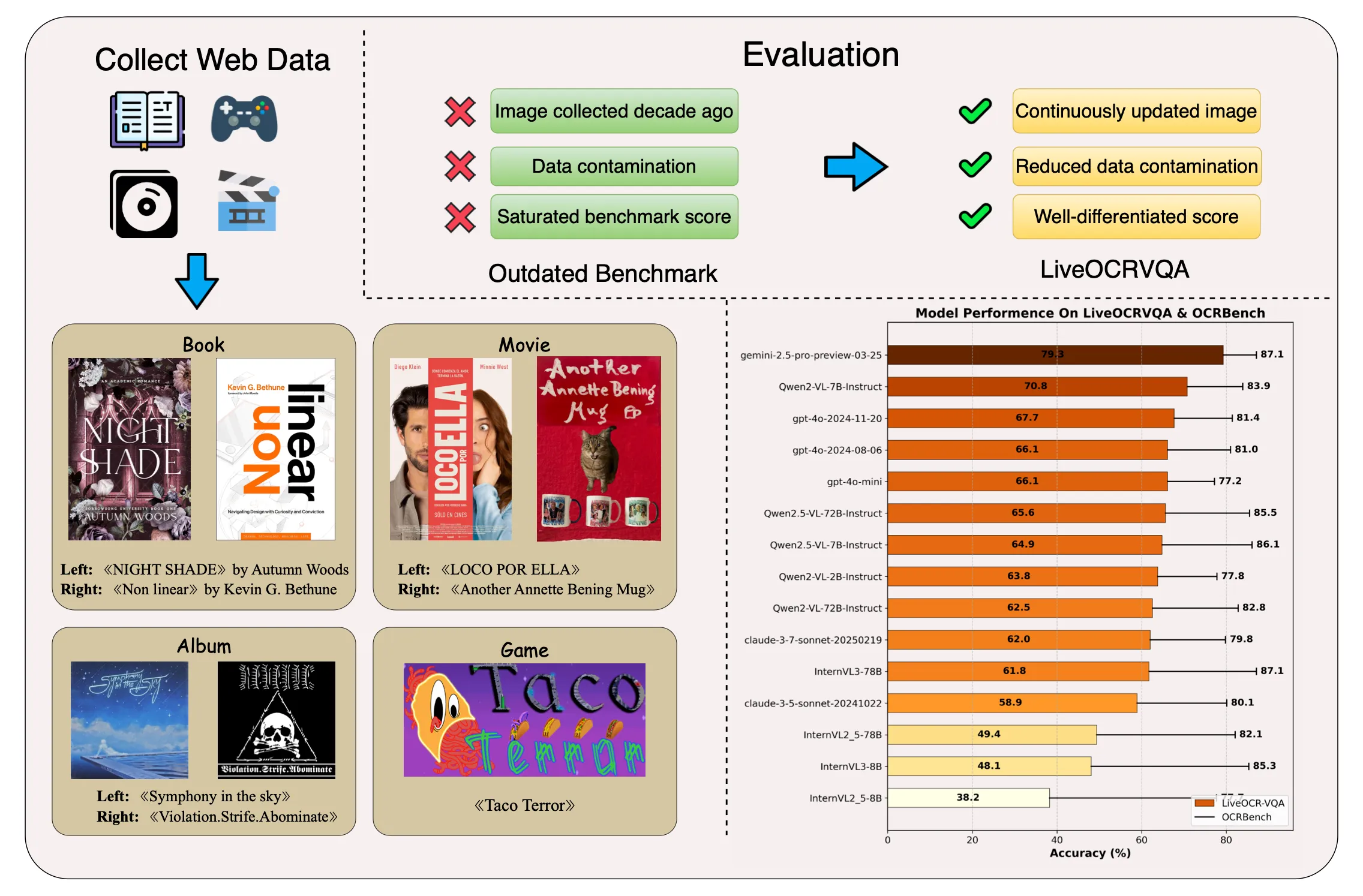
We introduce LiveOCRVQA, a dynamic benchmark designed to avoid contamination from models’ exposure to static, web-sourced data. Using a semi-automated pipeline, we continuously curate fresh images of stylized text—legible to humans but challenging for LMMs—and pair them with metadata across diverse sources. Our initial release comprises 385 instances, which we used to evaluate 21 leading models. Results reveal that many LMMs often fall back on memorized text or learned font/layout patterns rather than true character recognition. Both the dataset and evaluation suite are publicly available, and we will update them quarterly to track real-world text-understanding progress.
LiveOCRVQA comprises 385 stylized text-image instances across four categories—Books, Movies, Albums, and Games—with carefully curated question–answer pairs to evaluate text-understanding capabilities. Comparing to existing benchmarks, LiveOCRVQA is continuously updated to avoid contamination from models’ exposure to static, web-sourced data. Evaluation shows that well-differentiated score rather than saturated score is more meaningful for evaluating the ability of LMMs to understand stylized text.
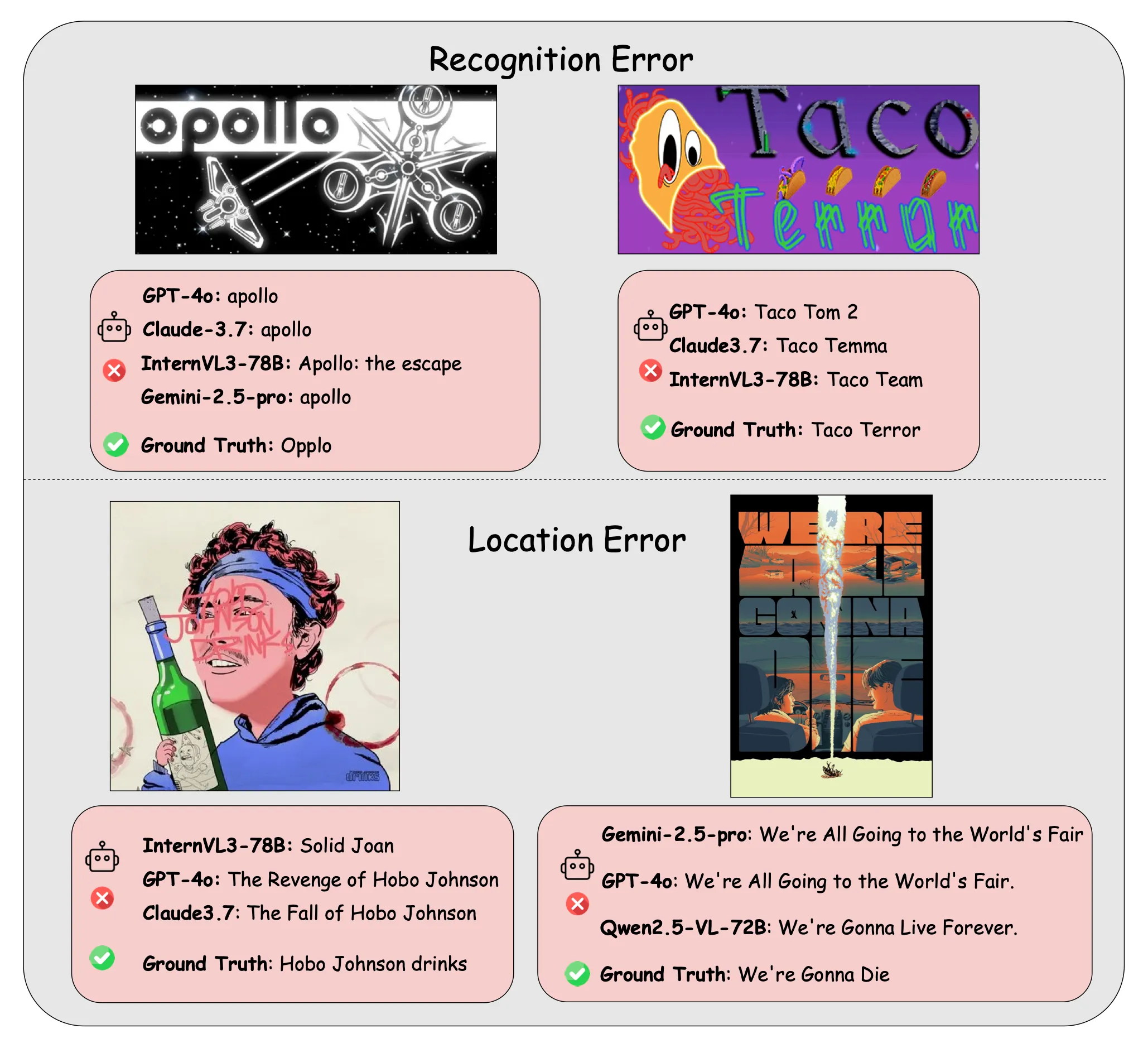
Examples illustrating LMMs produced typos in these specific, human-simple cases, including:
| Model | Overall | Album | Book | Game | Movie |
|---|---|---|---|---|---|
| Gemini-2.5-pro | 80.52% | 68.31% | 90.14% | 85.71% | 88.33% |
| Gemini-2.5-flash | 75.32% | 66.20% | 80.28% | 81.25% | 80.00% |
| Qwen2-VL-7B | 72.21% | 64.08% | 83.10% | 71.43% | 80.00% |
| GPT-4o-2411 | 69.09% | 57.04% | 90.14% | 74.11% | 63.33% |
| gpt-4o-mini | 67.53% | 54.93% | 83.10% | 70.54% | 73.33% |
| Qwen2.5-VL-72B | 67.27% | 53.52% | 71.83% | 75.00% | 80.00% |
| GPT-4o-2408 | 67.01% | 48.59% | 81.69% | 79.46% | 70.00% |
| Qwen2.5-VL-7B | 65.97% | 51.41% | 74.65% | 72.32% | 78.33% |
| Qwen2-VL-2B | 64.68% | 52.82% | 76.06% | 66.07% | 76.67% |
| Qwen2-VL-72B | 63.64% | 56.34% | 66.20% | 66.07% | 73.33% |
| InternVL3-78B | 63.64% | 54.23% | 67.61% | 68.75% | 71.67% |
| Claude-3-7-sonnet | 62.60% | 38.03% | 85.92% | 66.07% | 86.67% |
| Claude-3-5-sonnet | 59.74% | 39.44% | 76.06% | 62.50% | 83.33% |
| Pixtral-Large | 58.96% | 41.55% | 76.06% | 60.71% | 76.67% |
| InternVL2.5-78B | 50.65% | 43.66% | 54.93% | 53.57% | 56.67% |
| InternVL3-8B | 49.61% | 40.14% | 54.93% | 49.11% | 66.67% |
| LLaVA-OV-7b | 45.71% | 45.77% | 50.70% | 41.07% | 48.33% |
| InternVL2.5-8B | 39.22% | 30.28% | 52.11% | 41.07% | 41.67% |
| Phi-3.5-vision | 37.40% | 19.01% | 40.85% | 53.57% | 46.67% |
| Idefics3-8B | 28.05% | 29.58% | 39.44% | 17.86% | 30.00% |
| Phi-4-multimodal | 17.92% | 16.20% | 21.13% | 17.86% | 18.33% |
@misc{liu2025liveocrbench,
author = "{Yesheng Liu, Zheqi He, Jingshu Zheng, Jinge Yao, Xi Yang, Jiajun Zhang}",
title = "LiveOCRBench: Tracking Vision-Language Models' Persistent Struggles with Text Recognition",
year = "2025",
howpublished = "\url{https://flageval-baai.github.io/liveocrbench/}",
}