Recent vision-language models (VLMs) have demonstrated impressive performance in text recognition and understanding, as shown by the metrics on a number of text-centric benchmarks. In this study, we take a closer look at the current success. Following popularly used relevant benchmarks, we conduct more analysis on re-collected and edited data. We find that while modern VLMs are indeed showing strong text recognition and understanding capabilities, the strength might have been slightly over-estimated for some models with the risk of benchmark saturation and overfitting. We discuss the implications and prepare for TRUE, our new benchmark for Text Recognition and Understanding Evaluation, with regular updates in mind. The first version of our benchmark confirmed the huge advantage of very recently released top-tier VLMs, while also showing a bit room for further improvement. We hope our analysis and benchmark updates could help contribute to the development and evaluation of relevant progress in the near future.
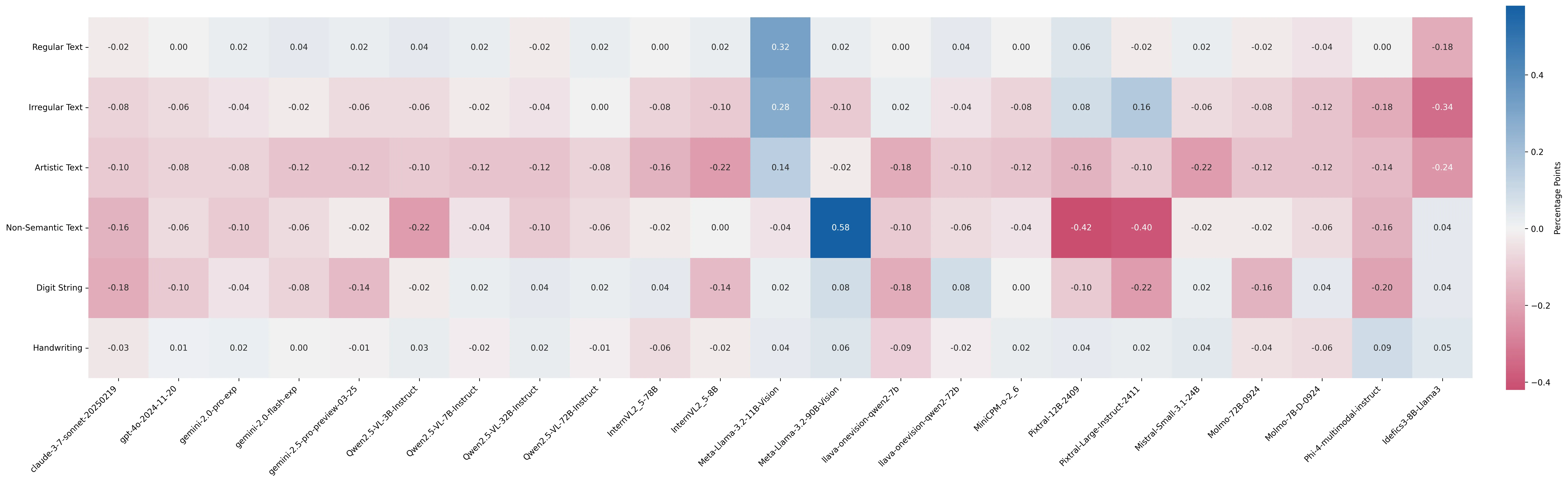
We conduct our analysis by using popular benchmarks as reference. For text recognition, we attempt at a replication of the recognition subsets in OCRBench. In brief, we strictly follow the data collection process of the source dataset. The performance of the current top-tier VLMs in Figure 1 shows distributional overfitting on text recognition tasks.
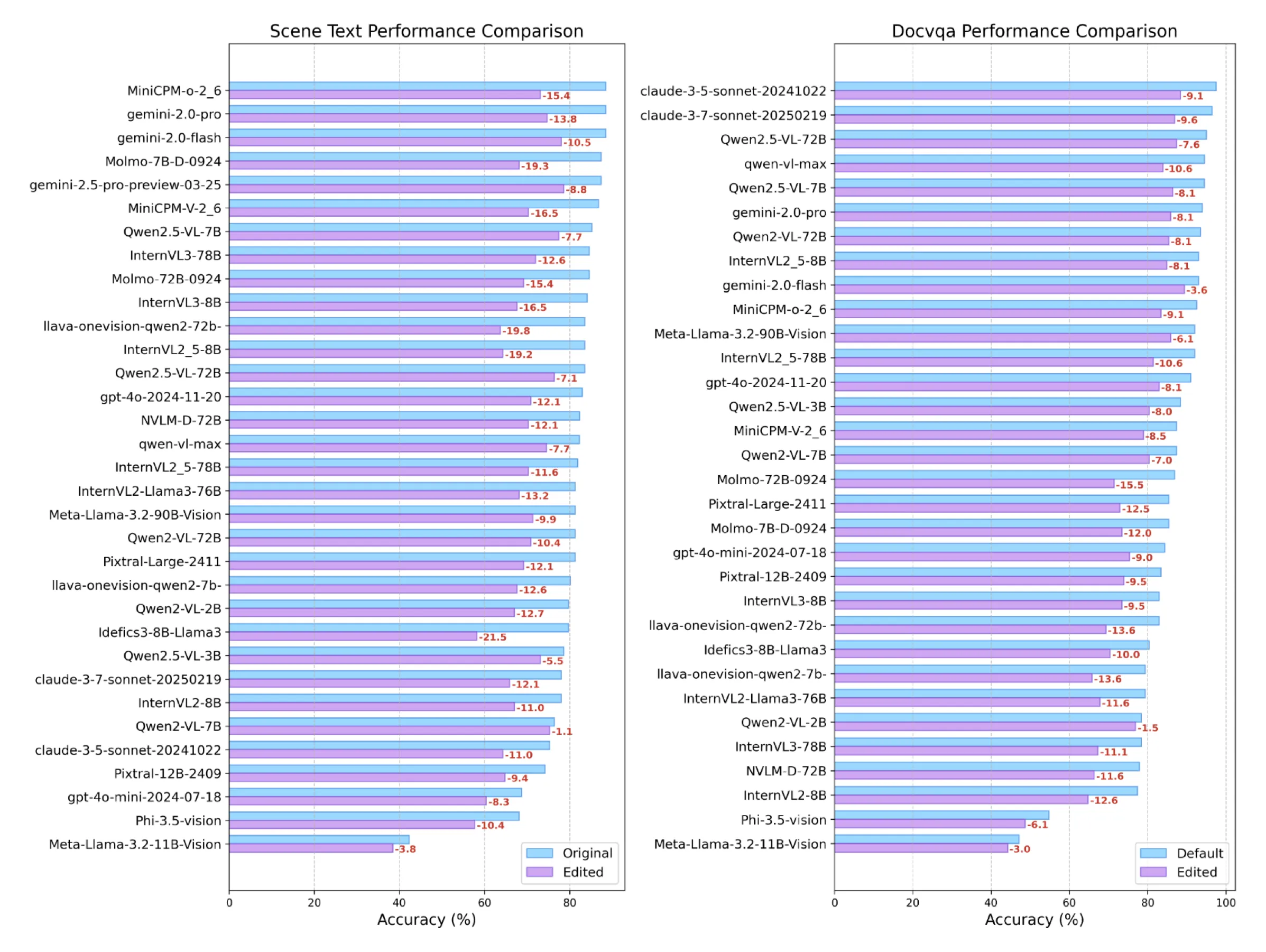
For text understanding, we conduct minimal perturbations on DocVQA and TextVQA, which means that only the area of target answer is changed, and any other visual element that has been semantically related to the old answer has been simultaneously modified. Two edited examples are shown in Figure 2:

Performance drops on edited images show that:
(1) Accuracy descent exists on both DocVQA and TextVQA.
(2) Text recognition and understanding in richer textual context(DocVQA) might be slightly more robust than recognizing text from scenes with very little textual context(TextVQA).
Based on our preliminary findings, We assemble our re-collection of new data as the first batch of our new benchmark, named Text Recognition and Understanding Evaluation suite (TRUE). The first version of our benchmark includes 1,146 image-text pairs (a subset of 573 forming a more challenging hard set), including:
SceneOCR: general scene-text recognition
HW: Handwriting recognition on paper, boards, or digital pages
SceneVQA: Scene-text understanding (VQA)
DocumentVQA: Document understanding (VQA)
ChartInfo: Chart and infographics understanding (VQA)
Receipt VQA: Receipt understanding
Food VQA: Food ingredients understanding on product packages
FB: Recognizing fake brands (recognition vs. language bias)
Book: Books on the Bookshelf (naturally rotated text)
Diet: Dietary VQA (understanding beyond ingredient extraction)








| Model | All | HW | SceneOCR | FakeBrands | BookVQA | DietVQA | Chart&Info | SceneVQA |
|---|---|---|---|---|---|---|---|---|
| gemini-2.5-pro-preview-03-25 | 81.6 | 88.2 | 68.4 | 67.9 | 95.4 | 68.8 | 83.6 | 80.3 |
| gemini-2.0-pro-exp | 75.0 | 73.7 | 73.7 | 75.0 | 82.9 | 70.5 | 72.6 | 69.0 |
| gemini-2.0-flash-exp | 75.0 | 89.5 | 54.4 | 67.9 | 91.1 | 65.2 | 72.6 | 69.0 |
| gpt-4o-2024-11-20 | 66.9 | 60.5 | 70.2 | 57.1 | 78.7 | 60.7 | 54.8 | 64.8 |
| claude-3-7-sonnet-20250219 | 51.7 | 60.5 | 35.1 | 28.6 | 38.5 | 61.6 | 75.3 | 62.0 |
| Qwen2.5-VL-72B-Instruct | 64.9 | 76.3 | 70.2 | 57.1 | 55.8 | 68.8 | 72.6 | 66.2 |
| InternVL2_5-78B | 60.9 | 50.0 | 45.6 | 50.0 | 72.4 | 63.4 | 57.5 | 54.9 |
| Qwen2.5-VL-32B-Instruct | 59.9 | 57.9 | 49.1 | 35.7 | 50.0 | 65.2 | 80.8 | 73.2 |
| Pixtral-Large-Instruct-2411 | 57.1 | 50.0 | 45.6 | 42.9 | 53.5 | 73.2 | 72.6 | 43.7 |
| Mistral-Small-3.1-24B | 51.2 | 73.7 | 31.6 | 17.9 | 47.7 | 54.5 | 72.6 | 49.3 |
| Qwen2.5-VL-7B-Instruct | 49.4 | 55.3 | 56.1 | 60.7 | 50.0 | 30.4 | 56.2 | 57.8 |
| Molmo-72B-0924 | 47.9 | 36.8 | 38.6 | 35.7 | 51.9 | 52.7 | 46.6 | 50.7 |
| Meta-Llama-3.2-90B-Vision | 41.5 | 21.1 | 54.4 | 21.4 | 55.7 | 28.6 | 49.3 | 31.0 |
| Pixtral-12B-2409 | 41.0 | 39.5 | 24.6 | 28.6 | 33.3 | 56.2 | 67.1 | 28.2 |
| MiniCPM-o-2_6 | 40.7 | 55.3 | 42.1 | 17.9 | 35.1 | 36.6 | 58.9 | 42.2 |
| InternVL2_5-8B | 38.0 | 26.3 | 38.6 | 25.0 | 39.7 | 36.6 | 46.6 | 38.0 |
| Molmo-7B-D-0924 | 32.8 | 18.4 | 40.4 | 35.7 | 34.2 | 23.2 | 39.7 | 38.0 |
| Qwen2.5-VL-3B-Instruct | 32.7 | 57.9 | 28.1 | 25.0 | 29.3 | 28.6 | 37.0 | 36.6 |
| llava-onevision-qwen2-72b | 31.8 | 10.5 | 42.1 | 21.4 | 0.6 | 62.5 | 50.7 | 47.9 |
| llava-onevision-qwen2-7b | 20.4 | 13.2 | 26.3 | 17.9 | 4.6 | 36.6 | 26.0 | 28.2 |
| Idefics3-8B-Llama3 | 16.6 | 5.3 | 3.5 | 7.1 | 17.2 | 22.3 | 21.9 | 21.1 |
| Meta-Llama-3.2-11B-Vision | 15.9 | 0.0 | 3.5 | 7.1 | 39.1 | 2.7 | 15.1 | 2.8 |
| Phi-4-multimodal-instruct | 15.4 | 2.6 | 10.5 | 14.3 | 3.5 | 20.5 | 35.6 | 26.8 |
@misc{baaiflageval2025true,
author = "{BAAI FlagEval Team}",
title = "A Status Check on Current Vision-Language Models in Text Recognition and Understanding",
year = "2025",
howpublished = "https://flageval-baai.github.io/TRUE/",
}